library(tidyverse)27 Facet wraps
Sometimes the easiest way to spot a trend is to chart a bunch of small things side by side. Edward Tufte, one of the most well known data visualization thinkers on the planet, calls this “small multiples” where ggplot calls this a facet wrap or a facet grid, depending.
One thing we noticed earlier in the semester – it seems that a lot of teams shoot worse as the season goes on. Do they? We could answer this a number of ways, but the best way to show people would be visually. Let’s use Small Multiples.
As always, we start with libraries.
We’re going to use the logs of college basketball games last season.
For this walkthrough:
And load it.
logs <- read_csv("data/logs20.csv")Rows: 11097 Columns: 43
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (6): HomeAway, Opponent, W_L, Team, Conference, season
dbl (35): Game, TeamScore, OpponentScore, TeamFG, TeamFGA, TeamFGPCT, Team3...
lgl (1): Blank
date (1): Date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Let’s narrow our pile and look just at the Big Ten.
big10 <- logs |> filter(Conference == "Big Ten")The first thing we can do is look at a line chart, like we have done in previous chapters.
ggplot() +
geom_line(data=big10, aes(x=Date, y=TeamFGPCT, group=Team)) +
scale_y_continuous(limits = c(0, .7))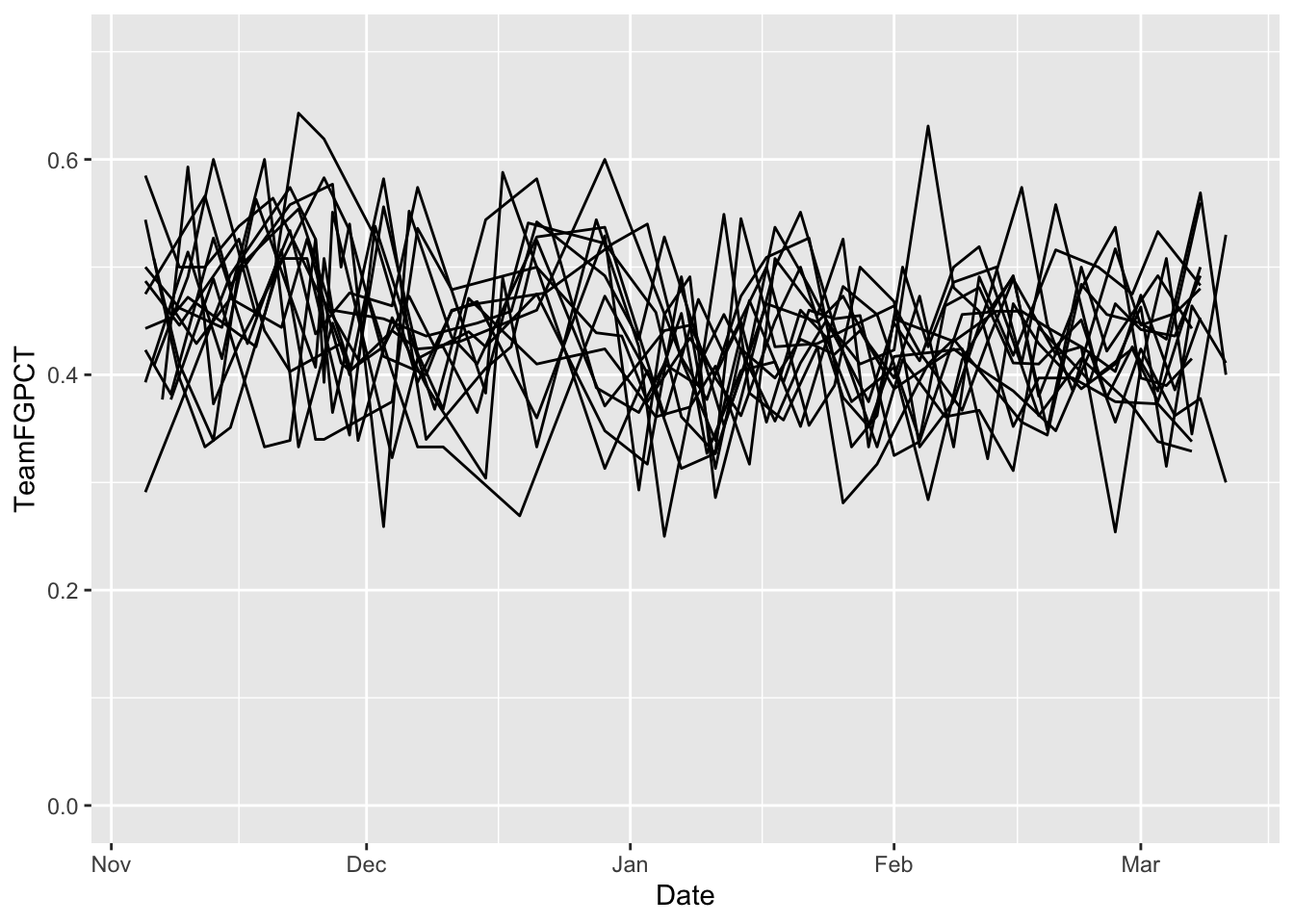
And, not surprisingly, we get a hairball. We could color certain lines, but that would limit us to focus on one team. What if we did all of them at once? We do that with a facet_wrap. The only thing we MUST pass into a facet_wrap is what thing we’re going to separate them out by. In this case, we precede that field with a tilde, so in our case we want the Team field. It looks like this:
ggplot() +
geom_line(data=big10, aes(x=Date, y=TeamFGPCT, group=Team)) +
scale_y_continuous(limits = c(0, .7)) +
facet_wrap(~Team)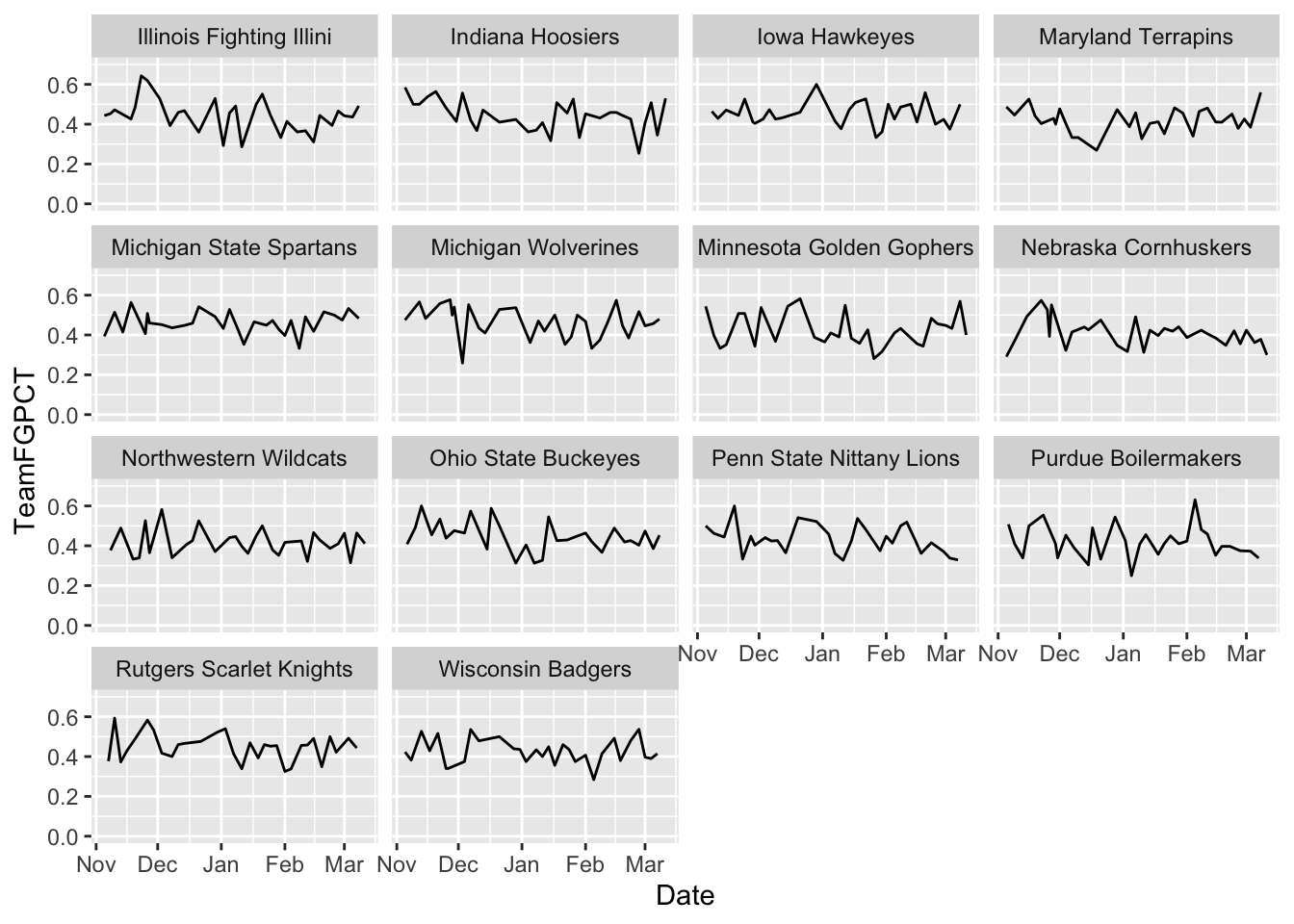
Answer: Not immediately clear, but we can look at this and analyze it. We could add a piece of annotation to help us out.
big10 |> summarise(mean(TeamFGPCT))# A tibble: 1 × 1
`mean(TeamFGPCT)`
<dbl>
1 0.436ggplot() +
geom_hline(yintercept=.4361078, color="blue") +
geom_line(data=big10, aes(x=Date, y=TeamFGPCT, group=Team)) +
scale_y_continuous(limits = c(0, .7)) +
facet_wrap(~Team)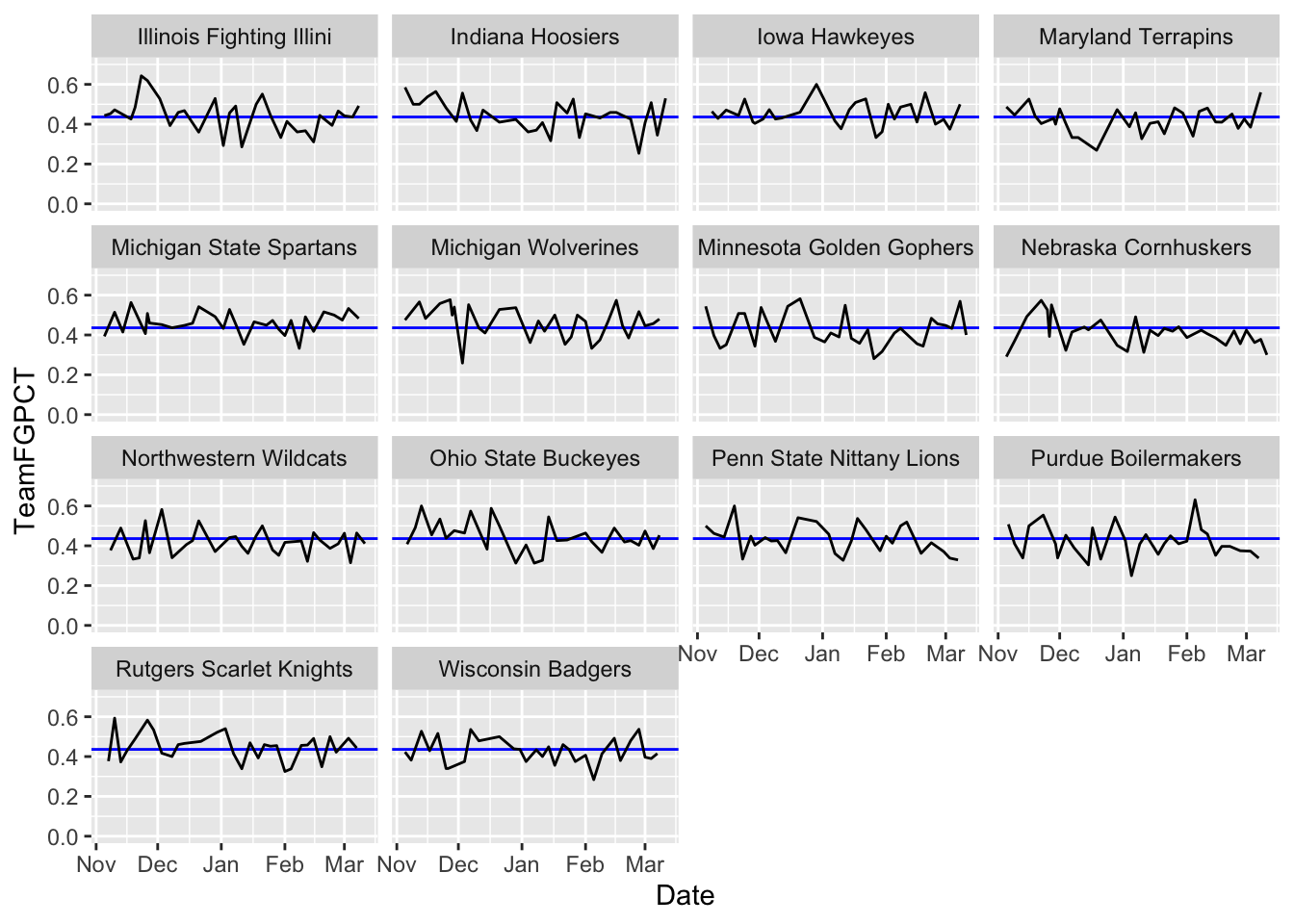
What do you see here? How do teams compare? How do they change over time? I’m not asking you these questions because they’re an assignment – I’m asking because that’s exactly what this chart helps answer. Your brain will immediately start making those connections.
27.1 Facet grid vs facet wraps
Facet grids allow us to put teams on the same plane, versus just repeating them. And we can specify that plane as vertical or horizontal. For example, here’s our chart from above, but using facet_grid to stack them.
ggplot() +
geom_hline(yintercept=.4361078, color="blue") +
geom_line(data=big10, aes(x=Date, y=TeamFGPCT, group=Team)) +
scale_y_continuous(limits = c(0, .7)) +
facet_grid(Team ~ .)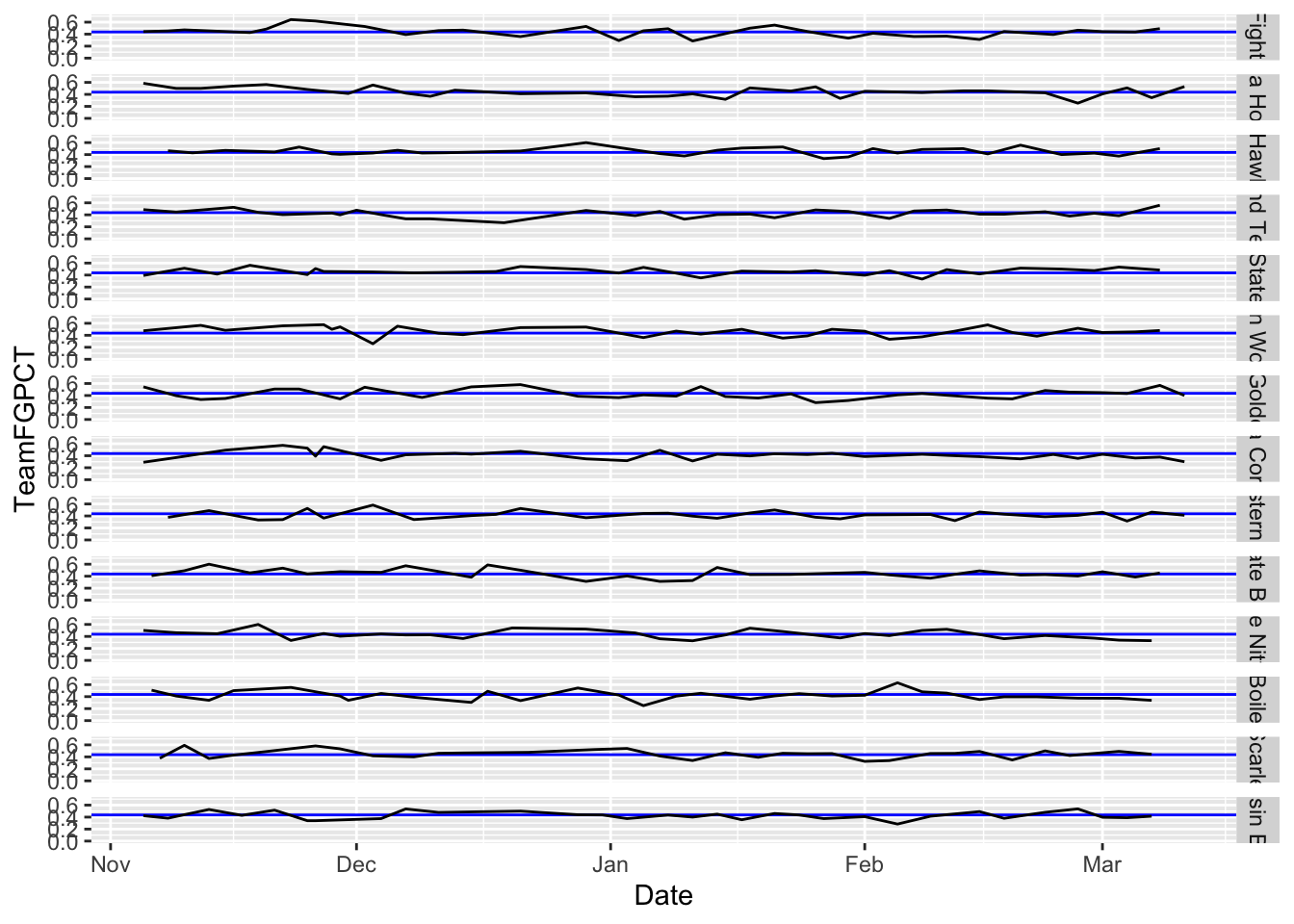
And here they are next to each other:
ggplot() +
geom_hline(yintercept=.4361078, color="blue") +
geom_line(data=big10, aes(x=Date, y=TeamFGPCT, group=Team)) +
scale_y_continuous(limits = c(0, .7)) +
facet_grid(. ~ Team)
Note: We’d have some work to do with the labeling on this – we’ll get to that – but you can see where this is valuable comparing a group of things. One warning: Don’t go too crazy with this or it loses it’s visual power.
27.2 Other types
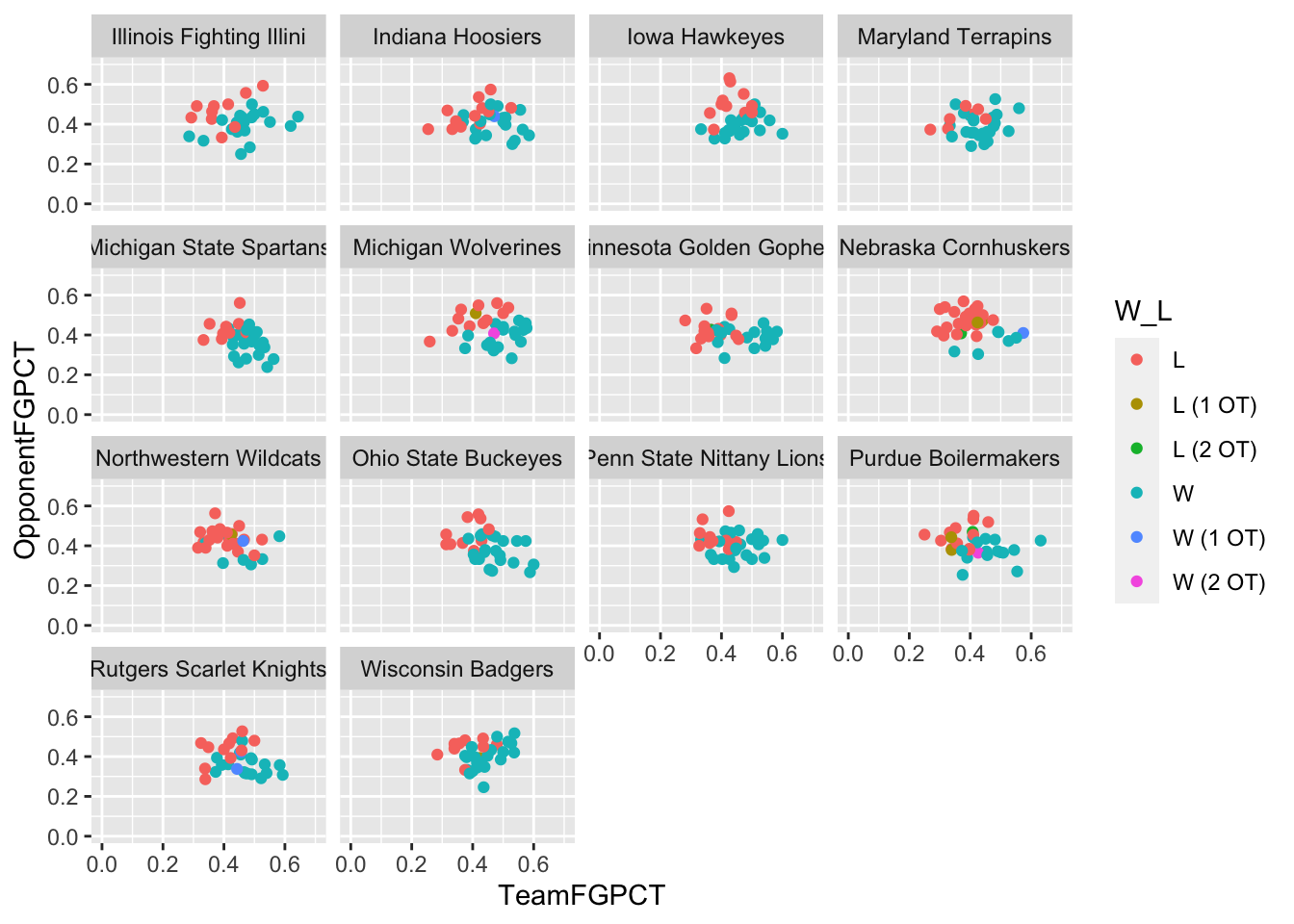
Line charts aren’t the only things we can do. We can do any kind of chart in ggplot. Staying with shooting, where are team’s winning and losing performances coming from when we talk about team shooting and opponent shooting?
ggplot() +
geom_point(data=big10, aes(x=TeamFGPCT, y=OpponentFGPCT, color=W_L)) +
scale_y_continuous(limits = c(0, .7)) +
scale_x_continuous(limits = c(0, .7)) +
facet_wrap(~Team)