library(tidyverse)11 Residuals
When looking at a linear model of your data, there’s a measure you need to be aware of called residuals. The residual is the distance between what the model predicted and what the real outcome is. Take our model at the end of the correlation and regression chapter. Our model predicted Nebraska, given a 5 net yardage margin would beat Iowa by 1.96 points. They lost by 6. So our residual is -7.96.
Residuals can tell you several things, but most important is if a linear model the right model for your data. If the residuals appear to be random, then a linear model is appropriate. If they have a pattern, it means something else is going on in your data and a linear model isn’t appropriate.
Residuals can also tell you who is underperforming and overperforming the model. And the more robust the model – the better your r-squared value is – the more meaningful that label of under or overperforming is.
Let’s go back to our net yards model.
For this walkthrough:
Then load the tidyverse.
logs <- read_csv("data/footballlogs20.csv")Rows: 1100 Columns: 54
── Column specification ────────────────────────────────────────────────────────
Delimiter: ","
chr (8): HomeAway, Opponent, Result, TeamFull, TeamURL, Outcome, Team, Con...
dbl (45): Game, PassingCmp, PassingAtt, PassingPct, PassingYds, PassingTD, ...
date (1): Date
ℹ Use `spec()` to retrieve the full column specification for this data.
ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.First, let’s make the columns we’ll need.
residualmodel <- logs |> mutate(differential = TeamScore - OpponentScore, NetYards = OffensiveYards - DefYards)Now let’s create our model.
fit <- lm(differential ~ NetYards, data = residualmodel)
summary(fit)
Call:
lm(formula = differential ~ NetYards, data = residualmodel)
Residuals:
Min 1Q Median 3Q Max
-49.479 -8.593 0.128 8.551 48.857
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 0.311030 0.385651 0.807 0.42
NetYards 0.101704 0.002293 44.345 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 12.78 on 1098 degrees of freedom
Multiple R-squared: 0.6417, Adjusted R-squared: 0.6414
F-statistic: 1967 on 1 and 1098 DF, p-value: < 2.2e-16We’ve seen this output before, but let’s review because if you are using scatterplots to make a point, you should do this. First, note the Min and Max residual at the top. A team has underperformed the model by nearly 50 points (!), and a team has overperformed it by 49 points (!!). The median residual, where half are above and half are below, is just slightly above the fit line. Close here is good.
Next: Look at the Adjusted R-squared value. What that says is that 64 percent of a team’s scoring output can be predicted by their net yards.
Last: Look at the p-value. We are looking for a p-value smaller than .05. At .05, we can say that our correlation didn’t happen at random. And, in this case, it REALLY didn’t happen at random. But if you know a little bit about football, it doesn’t surprise you that the more you outgain your opponent, the more you win by. It’s an intuitive result.
What we want to do now is look at those residuals. We want to add them to our individual game records. We can do that by creating two new fields – predicted and residuals – to our dataframe like this:
residualmodel <- residualmodel |> mutate(predicted = predict(fit), residuals = residuals(fit))Now we can sort our data by those residuals. Sorting in descending order gives us the games where teams overperformed the model. To make it easier to read, I’m going to use select to give us just the columns we need to see.
residualmodel |> arrange(desc(residuals)) |> select(Team, Opponent, Result, differential, NetYards, predicted, residuals)# A tibble: 1,100 × 7
Team Opponent Result differential NetYards predicted residuals
<chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 Arizona State Arizona W (70… 63 136 14.1 48.9
2 Wisconsin Wake Fore… W (42… 14 -252 -25.3 39.3
3 Kentucky Mississip… W (24… 22 -138 -13.7 35.7
4 Mississippi State Vanderbilt W (24… 7 -274 -27.6 34.6
5 Kansas State Kansas W (55… 41 61 6.51 34.5
6 Boise State Colorado … W (52… 31 -24 -2.13 33.1
7 Army Mercer W (49… 46 139 14.4 31.6
8 Notre Dame South Flo… W (52… 52 198 20.4 31.6
9 Texas Oklahoma … W (41… 7 -243 -24.4 31.4
10 BYU North Ala… W (66… 52 201 20.8 31.2
# ℹ 1,090 more rowsSo looking at this table, what you see here are the teams who scored more than their net yards would indicate. One of them should jump off the page at you.
Remember Nebraska vs Rutgers? We won and everyone was happy and relieved the season was over? We outgained Rutgers by 368 yards in that game and won by 7. Our model predicted Nebraska should have won that game by 37 points. We should have blown Rutgers out of their own barn. But Rutgers isn’t as hard done as Arizona, which should have lost by 48, but ended up losing by 63.
But, before we can bestow any validity on this model, we need to see if this linear model is appropriate. We’ve done that some looking at our p-values and R-squared values. But one more check is to look at the residuals themselves. We do that by plotting the residuals with the predictor. We’ll get into plotting soon, but for now just seeing it is enough.
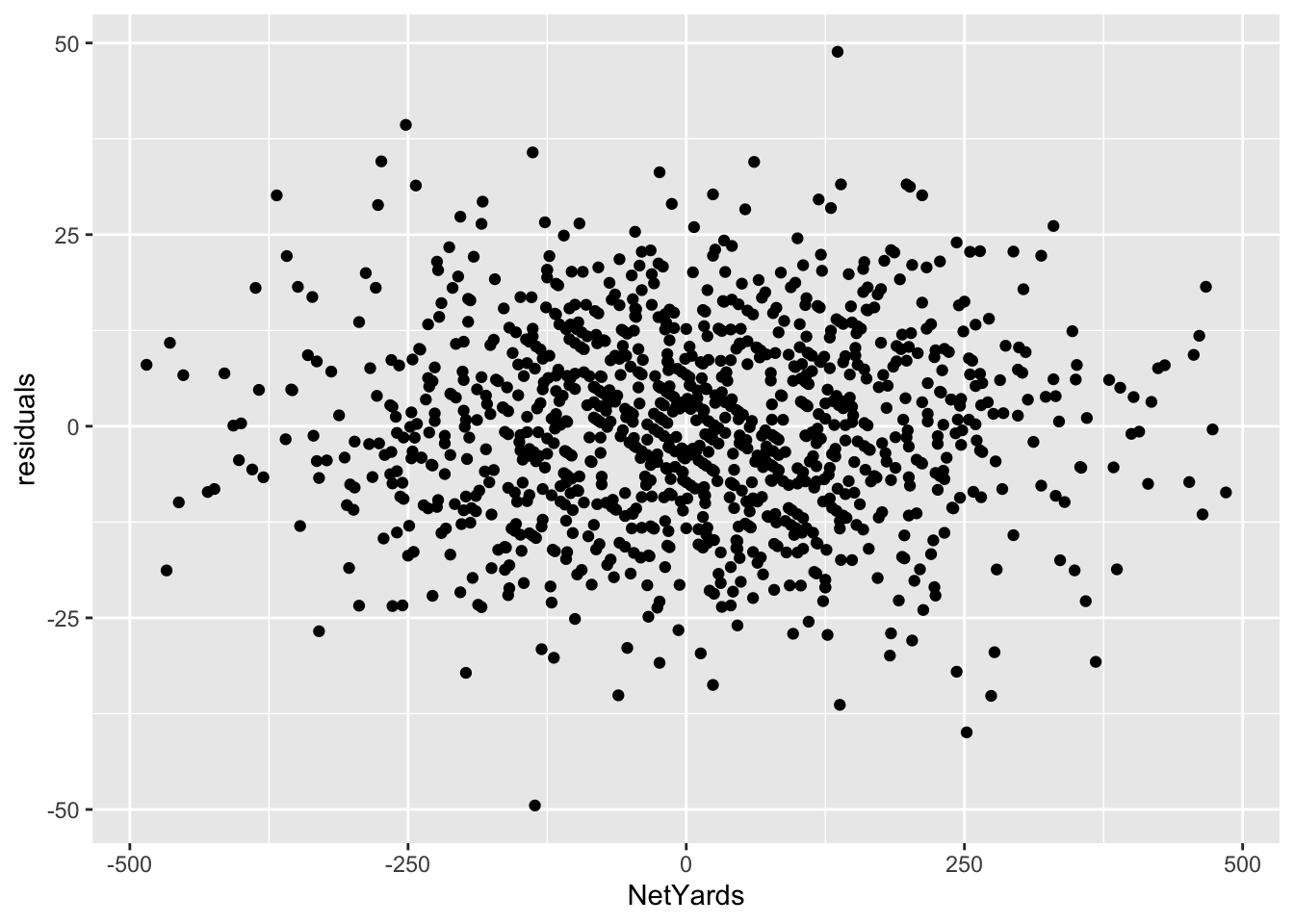
The lack of a shape here – the seemingly random nature – is a good sign that a linear model works for our data. If there was a pattern, that would indicate something else was going on in our data and we needed a different model.
Another way to view your residuals is by connecting the predicted value with the actual value.
`geom_smooth()` using formula = 'y ~ x'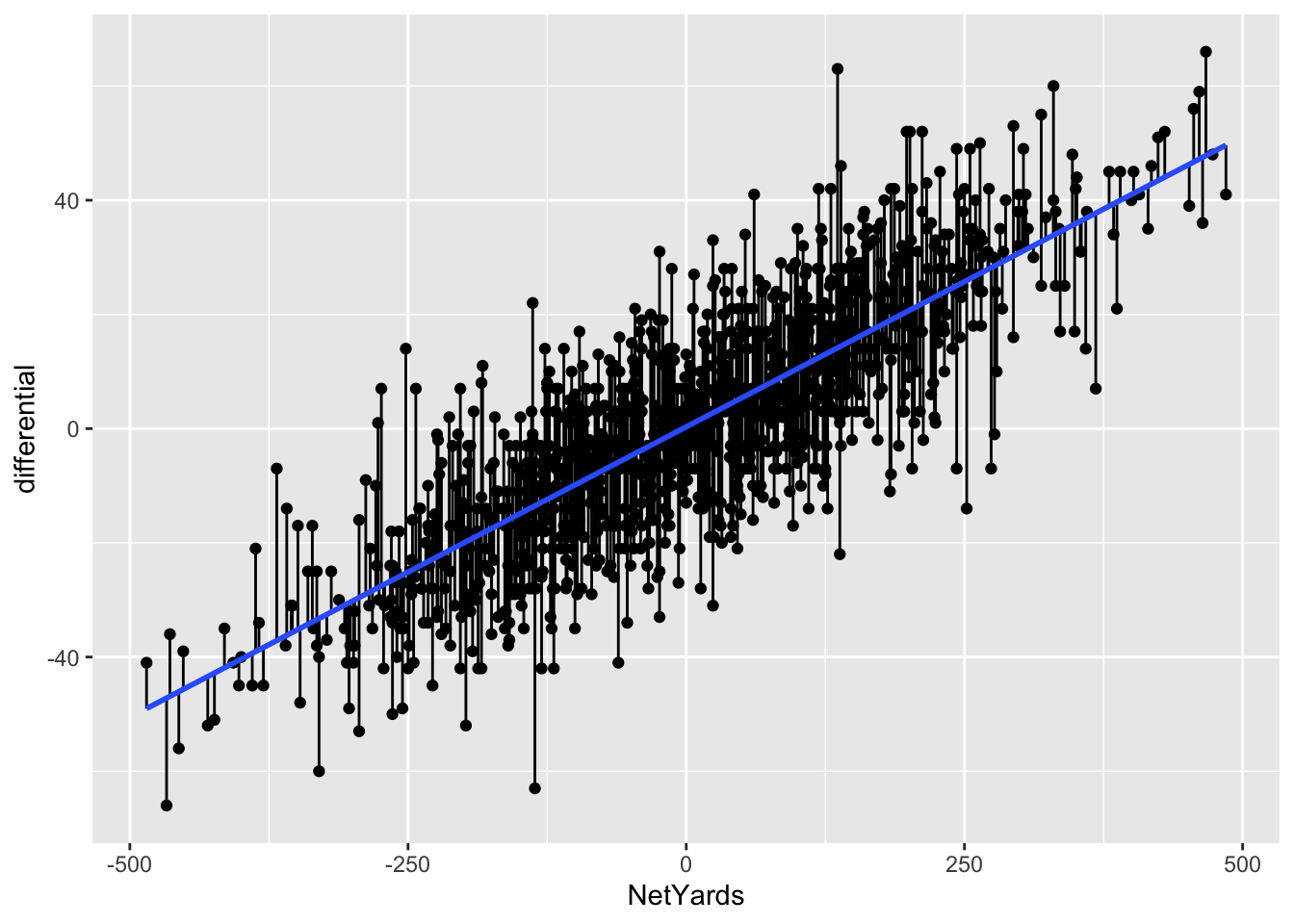
The blue line here separates underperformers from overperformers.
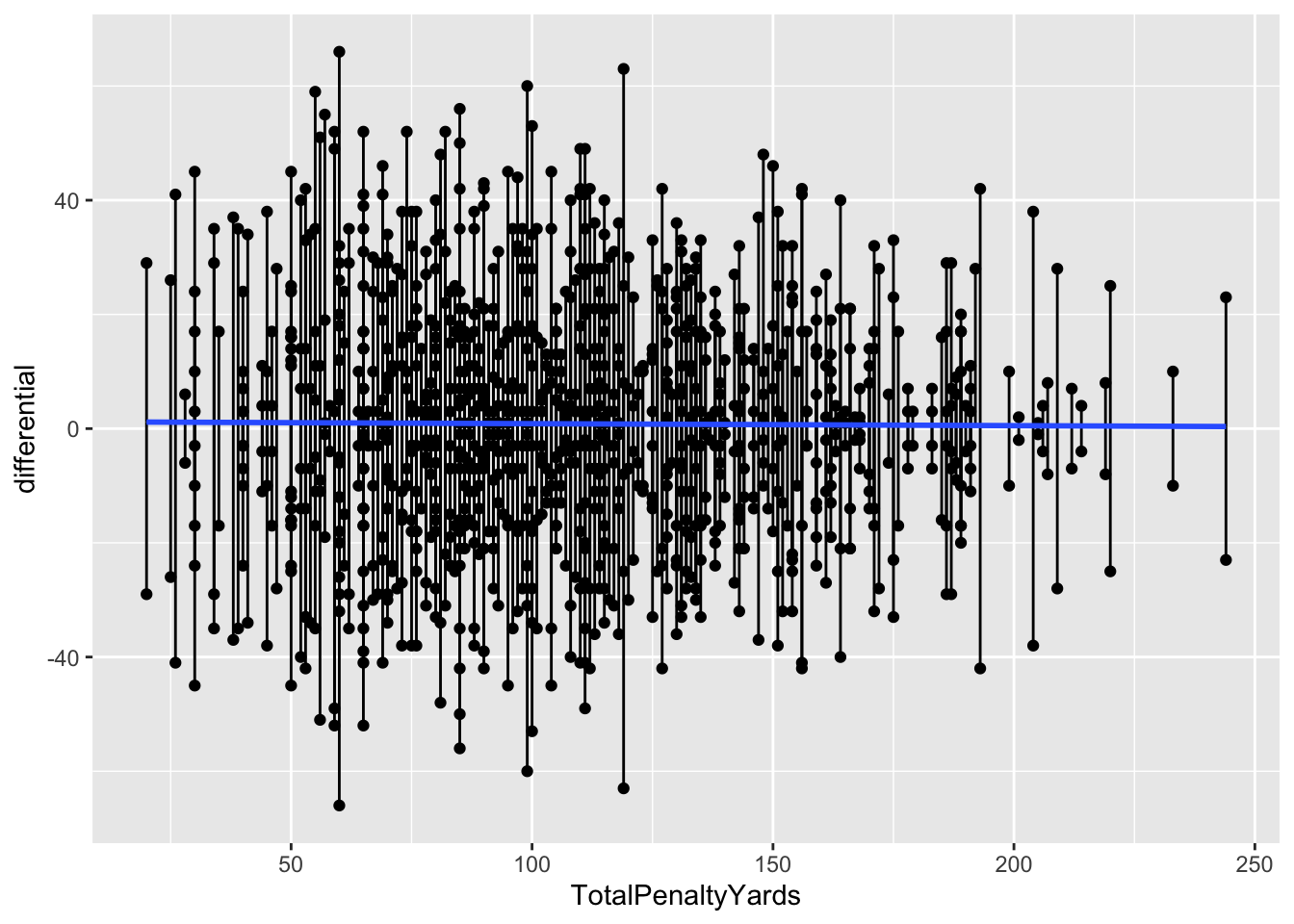
11.1 Penalties
Now let’s look at it where it doesn’t work: Penalties.
penalties <- logs |>
mutate(
differential = TeamScore - OpponentScore,
TotalPenalties = Penalties+DefPenalties,
TotalPenaltyYards = PenaltyYds+DefPenaltyYds
)pfit <- lm(differential ~ TotalPenaltyYards, data = penalties)
summary(pfit)
Call:
lm(formula = differential ~ TotalPenaltyYards, data = penalties)
Residuals:
Min 1Q Median 3Q Max
-67.007 -14.699 0.265 14.047 64.993
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.21614 1.79282 0.678 0.498
TotalPenaltyYards -0.00349 0.01556 -0.224 0.823
Residual standard error: 21.36 on 1098 degrees of freedom
Multiple R-squared: 4.58e-05, Adjusted R-squared: -0.0008649
F-statistic: 0.05029 on 1 and 1098 DF, p-value: 0.8226So from top to bottom:
- Our min and max go from -67 to positive 65
- Our adjusted R-squared is … -0.0008935. Not much at all.
- Our p-value is … 0.8307, which is more than than .05.
So what we can say about this model is that it’s statistically insignificant and utterly meaningless. Normally, we’d stop right here – why bother going forward with a predictive model that isn’t predictive? But let’s do it anyway.
penalties$predicted <- predict(pfit)
penalties$residuals <- residuals(pfit)penalties |> arrange(desc(residuals)) |> select(Team, Opponent, Result, TotalPenaltyYards, residuals)# A tibble: 1,100 × 5
Team Opponent Result TotalPenaltyYards residuals
<chr> <chr> <chr> <dbl> <dbl>
1 Clemson Georgia Tech W (73-7) 60 65.0
2 Arizona State Arizona W (70-7) 119 62.2
3 Alabama Kentucky W (63-3) 99 59.1
4 Marshall Eastern Kentucky W (59-0) 55 58.0
5 Texas Texas-El Paso W (59-3) 85 55.1
6 Pitt Austin Peay W (55-0) 57 54.0
7 Oklahoma Kansas W (62-9) 100 52.1
8 Wake Forest Campbell W (66-14) 82 51.1
9 BYU North Alabama W (66-14) 74 51.0
10 Notre Dame South Florida W (52-0) 65 51.0
# ℹ 1,090 more rowsFirst, note all of the biggest misses here are all blowout games. The worst games of the season, the worst being Clemson vs Georgia Tech. The model missed that differential by … 65 points. The margin of victory? 66 points. In other words, this model is terrible. But let’s look at it anyway.
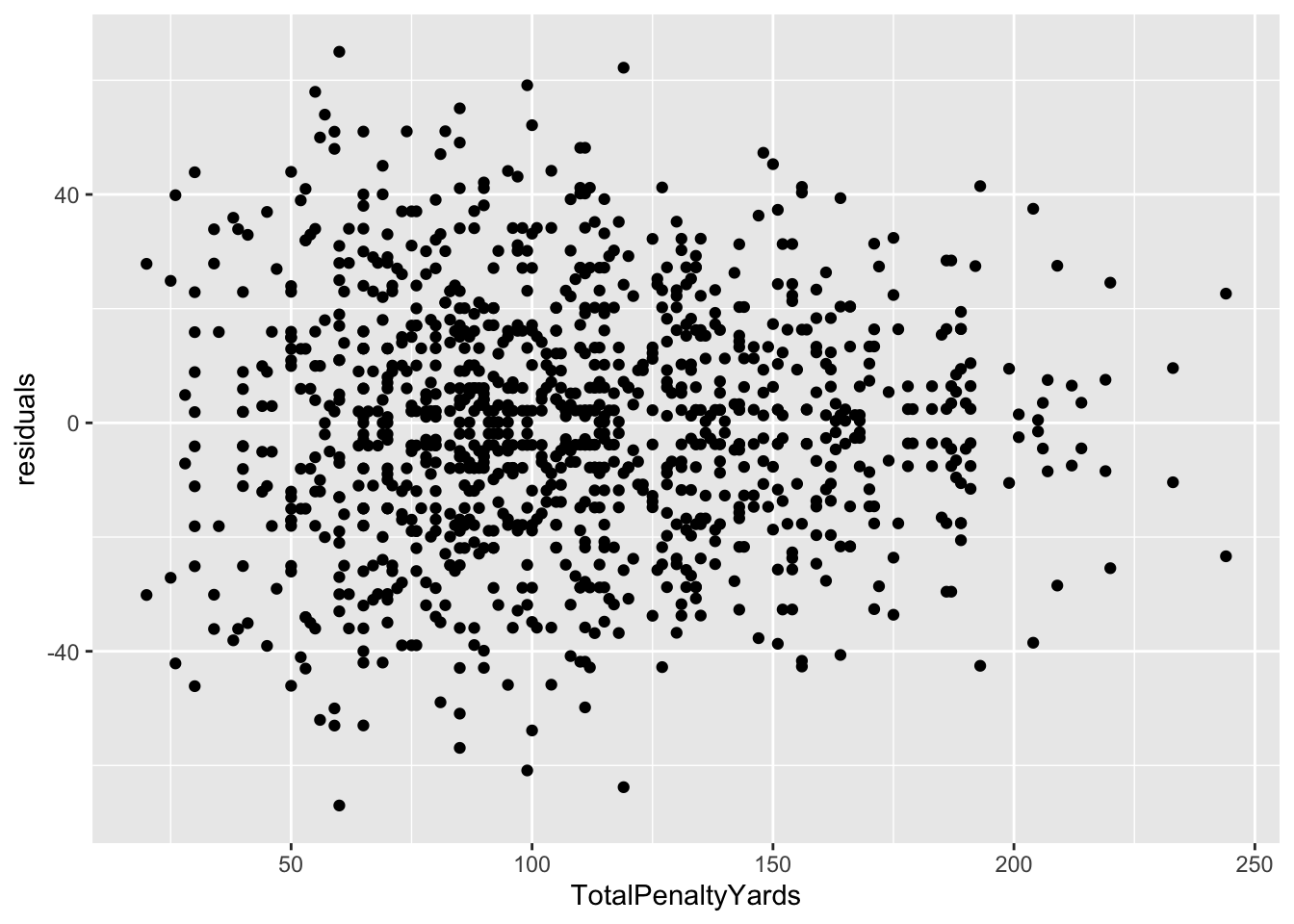
Well … it actually says that a linear model is appropriate. Which an important lesson – just because your residual plot says a linear model works here, that doesn’t say your linear model is good. There are other measures for that, and you need to use them.
Here’s the segment plot of residuals – you’ll see some really long lines. That’s a bad sign. Another bad sign? A flat fit line. It means there’s no relationship between these two things. Which we already know.
`geom_smooth()` using formula = 'y ~ x'